AernaLingus [any]
- 2 Posts
- 80 Comments
Joined 2 years ago
Cake day: May 6th, 2022
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

Davis states that the original source of the tale was Olayuk Narqitarvik. It was allegedly Olayuk’s grandfather in the 1950s who refused to go to the settlements and thus fashioned a knife from his own feces to facilitate his escape by skinning and disarticulating a dog. Davis has admitted that the story could be “apocryphal”, and that initially he thought the Inuit who told him this story was “pulling his leg”.
That’s a long payoff for a practical joke, but totally worth it.
Also, unsurprisingly, they won the 2020 Ig Nobel Prize in Materials Science (lol) for this one (video of the ceremony, Ig Nobel “lecture” from the lead author (also the primary pooper))
Written a bit more explicitly (although I kinda handwaved away the final term–the point is that you end up with one unpaired term which goes to zero)
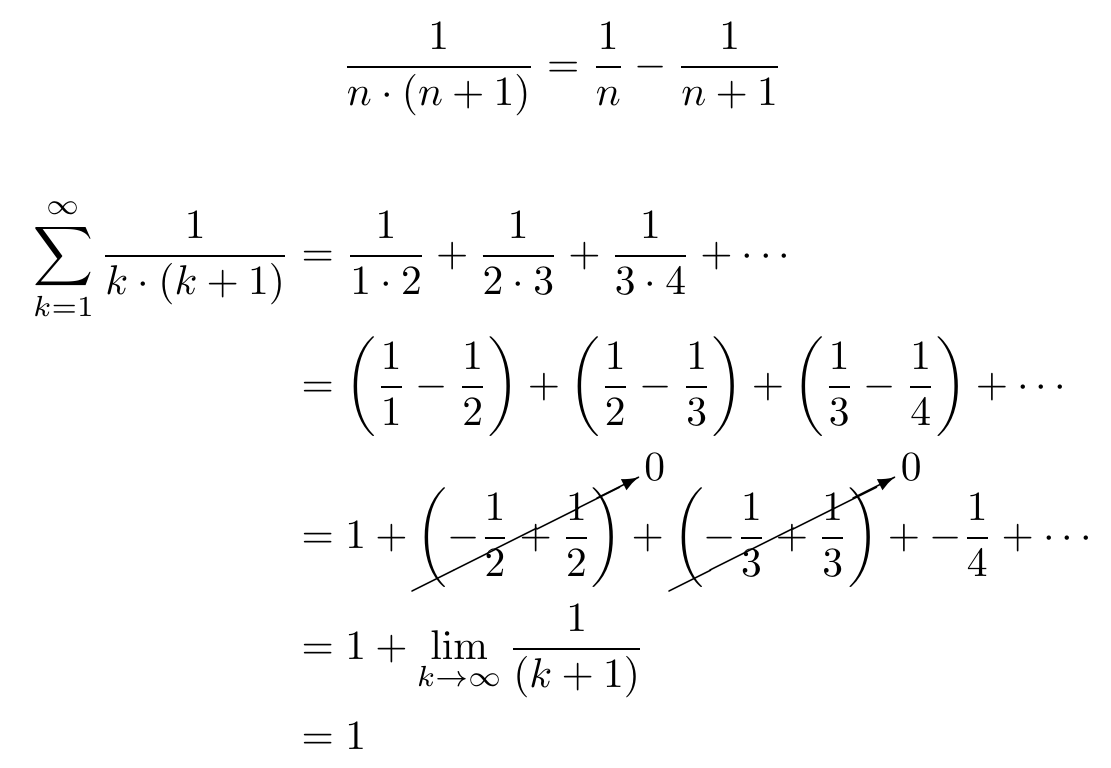
edit: I was honestly confused about how exactly this related to the question, but seeing the comment from @yetAnotherUser@discuss.tchncs.de (not visible from Hexbear) which showed that the first sum in the image is equivalent to
the sum from n = 1 to ∞ of 2/(n * (n + 1))
made things clear (just take the above, put 2 in the numerator, and you get a result of 2)
Obligatory Gianni Matragrano version (couldn’t find the original on his channel, idk if it’s from another platform or the video is no longer available or what)

 4·22 days ago
4·22 days agoFacebook (when that was still a platform young people used). I would obsessively scroll through it for hours each day, basically trying to look at and comment on EVERYTHING. On a whim, I decided to take a break from it for a month. By the time the month was up, I realized I didn’t miss it at all, and that was that. One of the big takeaways was that I thought that I was forming relationships with the people I’d comment back and forth with, but in reality these were people who I would never hang out with outside of school and barely even talk with in school (if at all); it was all just superficial, and I was better off spending time talking to my actual friends.
It wasn’t that bad, but in high school I mindlessly got into the habit of drinking a few cups of Coke each day (I think it started because I would get a 2 liter whenever I’d order pizza). I quit it pretty much cold turkey, and not only did I stop drinking it at home, I no longer order it at restaurants either, which is something I did ever since I was a little kid. The idea of just buying a bottle of soda and drinking it is straight honestly grosses me out now even though getting a can or bottle from a vending machine was something I’d do without thinking. The one exception is when I’m pigging out at the movies with a bucket of popcorn, but that’s pretty rare.

 10·23 days ago
10·23 days agoThis seemed obviously fake, but…it’s real.
 0·30 days ago
0·30 days agoYouTube URL without the tracking parameter:
 6·1 month ago
6·1 month agoThe original French quote appears to be from here. Stories link to another tweet (since privated) as the source of the translation, which quotes the first tweet, but it only differs from the embedded Google Translate result by a single word (“tasty” vs. “satisfying”). Here’s a video of the press conference with more context and a similar translation of that quote.
Whoa, that looks pretty sick. Definitely will give it a shot next time the need arises!
David P. Goldman is deputy editor of Asia Times and a fellow of the Claremont Institute’s Center for the American Way of Life.
What a fash-coded name for a think tank. Might as well call it the Center for Securing the Existence of Our People and a Future for White Children.
In text form:
Abstract
Amid the current U.S.-China technological race, the U.S. has imposed export controls to deny China access to strategic technologies. We document that these measures prompted a broad-based decoupling of U.S. and Chinese supply chains. Once their Chinese customers are subject to export controls, U.S. suppliers are more likely to terminate relations with Chinese customers, including those not targeted by export controls. However, we find no evidence of reshoring or friend-shoring. As a result of these disruptions, affected suppliers have negative abnormal stock returns, wiping out $130 billion in market capitalization, and experience a drop in bank lending, profitability, and employment.
Quote from conclusion
Moreover, the benefits of U.S. export controls, namely denying China access to advanced technology, may be limited as a result of Chinese strategic behavior. Indeed, there is evidence that, following U.S. export controls, China has boosted domestic innovation and self-reliance, and increased purchases from non-U.S. firms that produce similar technology to the U.S.-made ones subject to export controls.
A good example of this in action is detailed in a book called “how the workers’ parliaments saved the Cuban Revolution”, by Pedro Ross.
That sounds like a fascinating book! I’ve always been interested in the nitty gritty of how the Cuban democratic process works, and this book seems accessible and is just under 200 pages (not including the appendices/bibliography) so I might actually get through it.
Here’s a temporary download if anyone wants to grab it (it’s also just on libgen if you prefer to find it yourself)

Here’s an insta of an actual Japanese wildlife photographer chock-full of great photos of this bird (among others)
I went through a phase in my late teens/early 20s where I had major bladder shyness. There were a few times in especially high pressure situations (e.g. right after a movie or during a break in a football game) where I just stood there for 30 seconds with no results and was like “welp I guess I’m just gonna have to hold it until I get home.” I honestly don’t think I had any major psychological shift, since I was and still am majorly anxious, but thankfully it waned over time and I can now piss in peace.
 0·2 months ago
0·2 months agoWow, nice find! I was going to handle it by just arbitrarily picking the first tag which ended with
CreateDate,FileModifyDate, etc., but this is a much better solution which relies on the native behavior of exiftool. I feel kind of silly for not looking at the documentation more carefully: I couldn’t find anything immediately useful when looking at the documentation for the class used in the script (ExifToolHelper) but with the benefit of hindsight I now see this crucial detail about its parameters:All other parameters are passed directly to the super-class constructor:
exiftool.ExifTool.__init__()And sure enough, that’s where the
common_argsparameter is detailed which handles this exact use case:common_args (list of str*, or* None.) –
Pass in additional parameters for the stay-open instance of exiftool.
Defaults to
["-G", "-n"]as this is the most common use case.-
-G(groupName level 1 enabled) separates the output with groupName:tag to disambiguate same-named tags under different groups. -
-n(print conversion disabled) improves the speed and consistency of output, and is more machine-parsable
Passed directly into common_args property.
As for the renaming, you could handle this by using
os.path.existsas with the directory creation and using a bit of logic (along with the utility functionsos.path.basenameandos.path.splitext) to generate a unique name before the move operation:# Ensure uniqueness of path basename = os.path.basename(d['SourceFile']) filename, ext = os.path.splitext(basename) count = 1 while os.path.exists(f'{subdirectory}/{basename}'): basename = f'{filename}-{count}{ext}' count += 1 shutil.move(d['SourceFile'], f'{subdirectory}/{basename}')-
Alright, here’s what I’ve got!
#!/usr/bin/env python3 import datetime import glob import os import re import shutil import exiftool files = glob.glob(r"/path/to/photos/**/*", recursive=True) # Necessary to avoid duplicate files; if all photos have the same extension # you could simply add that extension to the end of the glob path instead files = [f for f in files if os.path.isfile(f)] parent_dir = r'/path/to/sorted/photos' start_date = datetime.datetime(2015, 1, 1) end_date = datetime.datetime(2024, 12, 31) date_extractor = re.compile(r'^(\d{4}):(\d{2}):(\d{2})') with exiftool.ExifToolHelper() as et: metadata = et.get_metadata(files) for d in metadata: for tag in ["EXIF:DateTimeOriginal", "EXIF:CreateDate", "File:FileModifyDate", "EXIF:ModifyDate", "XMP:DateAcquired"]: if tag in d.keys(): # Per file logic goes here year, month, day = [int(i) for i in date_extractor.match(d[tag]).group(1, 2, 3)] filedate = datetime.datetime(year, month, day) if filedate < start_date or filedate > end_date: break # Can uncomment below line for debugging purposes # print(f'{d['File:FileName']} {d[tag]} {year}/{month}') subdirectory = f'{parent_dir}/{year}/{month}' if not os.path.exists(subdirectory): os.makedirs(subdirectory) shutil.move(d['SourceFile'], subdirectory) breakOther than PyExifTool which will need to be installed using
pip, all libraries used are part of the standard library. The basic flow of the script is to first grab metadata for all files using oneexiftoolcommand, then for each file to check for the existence of the desired tags in succession. If a tag is found and it’s within the specified date range, it creates the YYYY/MM subdirectory if necessary, moves the file, and then proceeds to process the next file.In my preliminary testing, this seemed to work great! The filtering by date worked as expected, and when I ran it on my whole test set (831 files) it took ~6 seconds of wall time. My gut feeling is that once you’ve implemented the main optimization of handling everything with a single execution of
exiftool, this script (regardless of programming language) is going to be heavily I/O bound because the logic itself is simple and the bulk of time is spent reading and moving files, meaning your drive’s speed will be the key limiting factor. Out of those 6 seconds, only half a second was actual CPU time. And it’s worth keeping in mind that I’m doing this on a speedy NVME SSD (6 GB/s sequential read/write, ~300K IOPS random read/write), so it’ll be slower on a traditional HDD.There might be some unnecessary complexity for some people’s taste (e.g. using the
datetimetype instead of simple comparisons like in your bash script), but for something like this I’d prefer it to be brittle and break if there’s unexpected behavior because I parsed something wrong or put in nonsensical inputs rather than fail silently in a way I might not even notice.One important caveat is that none of my photos had that
XMP:DateAcquiredtag, so I can’t be certain that that particular tag will work and I’m not entirely sure that will be the tag name on your photos. You may want to run this tiny script just to check the name and format of the tag to ensure that it’ll work with my script:#!/usr/bin/env python3 import exiftool import glob import os files = glob.glob(r"/path/to/photos/**/*", recursive=True) # Necessary to avoid duplicate files; if all photos have the same extension # you could simply add that extension to the end of the glob path instead files = [f for f in files if os.path.isfile(f)] with exiftool.ExifToolHelper() as et: metadata = et.get_metadata(files) for d in metadata: if "XMP:DateAcquired" in d.keys(): print(f'{d['File:FileName']} {d[tag]}')If you run this on a subset of your data which contains XMP-tagged files and it correctly spits out a list of files plus the date metadata which begins
YYYY:MM:DD, you’re in the clear. If nothing shows up or the date format is different, I’d need to modify the script to account for that. In the former case, if you know of a specific file that does have the tag, it’d be helpful to get the exact tag name you see in the output from this script (I don’t need the whole output, just the name of the DateAcquired key):#!/usr/bin/env python3 import exiftool import json with exiftool.ExifToolHelper() as et: metadata = et.get_metadata([r'path/to/dateacquired/file']) for d in metadata: print(json.dumps(d, indent=4))If you do end up using this, I’ll be curious to know how it compares to the
parallelsolution! If theexiftoolstartup time ends up being negligible on your machine I’d expect it to be similar (since they’re both ultimately I/O bound, andparallelsaves time by being able to have some threads executing while others are waiting for I/O), but if theexiftoolspin-up time constitutes a significant portion of the execution time you may find it to be faster! If you don’t end up using it, no worries–it was a fun little exercise and I learned about a library that will definitely save me some time in the future if I need to do some EXIF batch processing!
Yeah, I think the fact that you need to capture the output and then use that as input to another exiftool command complicates things a lot; if you just need to run an exiftool command on each photo and not worry about the output I think the
-stay_openapproach would work, but I honestly have no idea how you would juggle the input and output in your case.Regardless, I’m glad you were able to see some improvement! Honestly, I’m the wrong person to ask about bash scripts, since I only use them for really basic stuff. There are wizards who do all kinds of crazy stuff with bash, which is incredibly useful if you’re trying to create a portable tool with no dependencies beyond any binaries it may call. But personally, if I’m just hacking myself together something good enough to solve a one-off problem for myself I’d rather reach for a more powerful tool like Python which demands less from my puny brain (forgive my sacrilege for saying this in a Bash community!). Here’s an example of how I might accomplish a similar task in Python using a wrapper around exiftool which allows me to batch process all the files in one go and gives me nice structured data (dictionaries, in this case) without having to do any text manipulation:
import exiftool import glob files = glob.glob(r"/path/to/photos/**/*", recursive=True) with exiftool.ExifToolHelper() as et: metadata = et.get_metadata(files) for d in metadata: for tag in ["EXIF:DateTimeOriginal", "EXIF:CreateDate", "File:FileCreateDate", "File:FileModifyDate", "EXIF:DateAcquired"]: if tag in d.keys(): # Per file logic goes here print(f'{d["File:FileName"]} {d[tag]}') breakThis outline of a script (which grabs the metadata from all files recursively and prints the filename and first date tag found for each) ran in 4.2 s for 831 photos on my machine (so ~5 ms per photo).
Since I’m not great in bash and not well versed in exiftool’s options, I just want to check my understanding: for each photo, you want to check if it’s in the specified date range, and then if it is you want to copy/move it to a directory of the format YYYYMMDD? I didn’t actually handle that logic in the script above, but I showed where you would put any arbitrary operations on each file. If you’re interested, I’d be happy to fill in the blank if you can describe your goal in a bit more detail!




May 4 fell on a Thursday most recently in 2023, 2017, and 2006. That build screams 2006, but both the Core 2 Duo and the x1950 Pro wouldn’t be out until later that year, and there wouldn’t actually be a Core 2 Duo with those specs until 2008 (the E8500 with 3.2 GHz–as far as I can tell there was never a Core 2 Duo with a precisely 3.2 GHz base clock). So this would have been a build that was quite long in the tooth when this was made (assuming it was made through texting a buddy and not a janky meme generator).