

For those who find it interesting, enjoy!
It gets me every time seeing people using the product I build 🥹
You worked on Grafana? Your product is awesome, I use it in my homelab for performance metrics
Yes, I’m one of the designers 👍🏾
deleted by creator
That’s so cool! Grafana is awesome, the whole team did a great job
Love Grafana, especially the new UI. Great work, man. :)
Poggers. Couldn‘t live wuthout it. Thank you for your work!
Thank you very much.
Do you work on Loci too?
Grafana is one of those tools which everyone should use if they have something they maintain themselves. Superb tool.
Grafana is the most essential application in my job. I can use Notepad to code in a world without IDEs. I couldn’t keep a damn thing running in the real world without Grafana. And I’ve been forced against my will to use alternatives in the past.
How did you learn it?
Basically brute force, I’m not great with it but I was the one on my team responsible for setting up our dashboards. I wrote the prometheus metric collection in our microservices and built the dashboards from that data.
There are tons of free dashboards though for monitoring resources and such so a lot of things I use are just downloaded from the Grafana website. And the docs are good too. So looking at examples + documentation is how I learn. It would be helpful if I was better with math though.
I guess it’s time to start browsing the dashboards thanks
You work at Grafana?
How far do you see lemmy.world capable of scaling to? One thing I’ve been noticing is the centralisation of Lemmy users on a few top servers, surely that cannot be healthy for federation? What are your thoughts on this?
@ruud@lemmy.world They should post their clustered setup so others can replicate more easily. It sounded like they had several webservers in front of a database (hopefully a cache box too).
Not entirely sure of what you are asking, but the only reason they need a clustered setup is simply because of their scale. Making the details of their setup public does not help with the issue I addressed, since in an ideal scenario, communities and users would be evenly distributed amongst the many Lemmy instances in the fediverse, making the need to do any sort of clustering for performance reasons unnecessary.
What I mean is if they post the specifics on how they setup a cluster of servers, other instance operators or people who want to start their own instance could more easily do so or just get off a single server configuration. No Lemmy instance should really be running on a single non-redundant box anyways, even if it’s only 2 small servers.
We do run on 1 server, but we’ve now seen that Lemmy scales horizontally so the k8s path forward is open 😊 With all these latest improvements we can have a bit more users on the current box.
Oh, I could a swore I read somewhere you went multi. Maybe I’m confusing another instance
Not trying to be pedantic, but why do they have to do so? Why can’t people figure it out themselves? Also, why can’t Lemmy instances run on single non-redundant boxes? Most instance operators don’t have the budget of enterprises, so why would they have to run their Lemmy’s like enterprises?
Not trying to be pedantic, but why do they have to do so? Why can’t people figure it out themselves?
Er, because we should all be working together to try to help Lemmy grow and be stable…? Because good-will and being nice and helpful to each other is intrinsically good?
Also, why can’t Lemmy instances run on single non-redundant boxes? Most instance operators don’t have the budget of enterprises, so why would they have to run their Lemmy’s like enterprises?
You can run on a single box, but a single problem will bring down your single box. This is a basic problem commonly discussed in DevOps circles.
Multi-server or containerized deploys aren’t only achievable by enterprise level companies. For example, one reasonably priced server on most providers is like $20-40/month. Say a load balancer as a service is another $10-20, and a database server or database as a service is also like $20-$40. A distributed, redundant setup would be like 2 webservers, a database, and a load balancer so like, $70? Maybe add in another server as a file host if Lemmy needs it (wordpress does iirc), or an additional caching server at a cheaper cost. And then you have a more stable service that can handle usage spikes better and users are more likely to stay around.
I’ve deployed clustered applications myself, I just haven’t looked into doing it with Lemmy and was curious if they had a run book or documentation.
Edit: or you use kubernetes or kubernetes as a service like ruud is saying they might look into. Could probably get it at the same cost.
Er, because we should all be working together to try to help Lemmy grow and be stable…?
I agree with this point, but I disagree with the context in which you mentioned, “They should post their clustered setup so others can replicate more easily”, right as a reply to my original comment asking how Ruud felt about the centralisation of users in a federated application. This should’ve been an entirely separate reply, or perhaps an issue on GitHub to the Lemmy authors.
You can run on a single box, but a single problem will bring down your single box. This is a basic problem commonly discussed in DevOps circles.
Again, I agree, but the context in which you mentioned it, basically suggests that everyone who runs single instance Lemmys are doing it wrong, which I disagree.
Lowering the entry requirements is part of how we can get wide-spread adoption of federated software. Not telling people that they have to have at least 2 instances with redundancies or they are doing it entirely wrong.
The bare minimum I would ask anyone running their own instance, is to have backups. They don’t need fancy load-balancers, or slaved Postgres database setups, or even multi-node redis caches for their instances of sub-thousand users.
For example, one reasonably priced server on most providers is like $20-40/month. Say a load balancer as a service is another $10-20, and a database server or database as a service is also like $20-$40. A distributed, redundant setup would be like 2 webservers, a database, and a load balancer so like, $70?
Seriously? That may be an acceptable price tag for a extremely public Lemmy host, like lemmy.world or lemmy.ml, but in no way should it be a reasonable price tag for the vast majority of Lemmy instances setup out there. Especially when most of them have sub-thousand users. $70/mo? That has to be a joke. You can easily host a Lemmy on a $5-$10 droplet for ~100 users.
I’ve deployed clustered applications myself, I just haven’t looked into doing it with Lemmy and was curious if they had a run book or documentation.
No offense, but you definitely seem like the kind of person to shill for cloud-scaling and disregard cost-savings.
Personally I can’t see a use-case for an instance that has ~100 users, people would just get bored and stop using it and move on to a more popular one. It’s not like a Minecraft server. Having people use a social media tool like Lemmy or a sub on Reddit is about having a critical mass of interesting content and users. But if there is such a small community, sure a single box is fine.
And load balancers are hardly fancy… if you know how to setup a webserver and write an nginx configuration, it’s like the next step of understanding. Digital ocean makes it incredibly easy.
I really enjoy your transparency and style of communication!
Comparing it to Spez and how Reddit became prior to the migration, this is such a refreshing change
/u/Ruud is like /u/Spez but only if /u/Spez was actually cool.
Sooo… /u/Ruud is nothing like /u/Spez? Same energy as “Communism is like Capitalism but only if Capitalism got rid of the concept of capital”.
Yes that was the joke.
It’s been very snappy today, nice work! Is it all under Docker Compose with the node handling Nginx and Postgres as well?
Yes.
I‘m really grateful for your and your colleagues‘ work. Thank you for letting us lemmy around here!!!
Why did you guys roll back the UI to .7 from .10? I enjoyed some of the UI improvements, but I guess there were some bugs?
Edit: I see its back to .10 maybe I had a browser tab open from before that I never refreshed
I can’t believe how fast you’ve managed to crowdsource and fix things on this instance. I haven’t seen many problems at all sharing comments and things.
Can someone give me a hand. I see tons of posts of people talking about a picture in the OP but i see nothing. Am i doing something wrong? Is my connection bad? This seems to be happening quite a lot. For example the meme instance has almost zero pictures but i know just about every post should have one.
hmm yeah it was gone… need to investigate…
How can I throw some bucks in your direction?
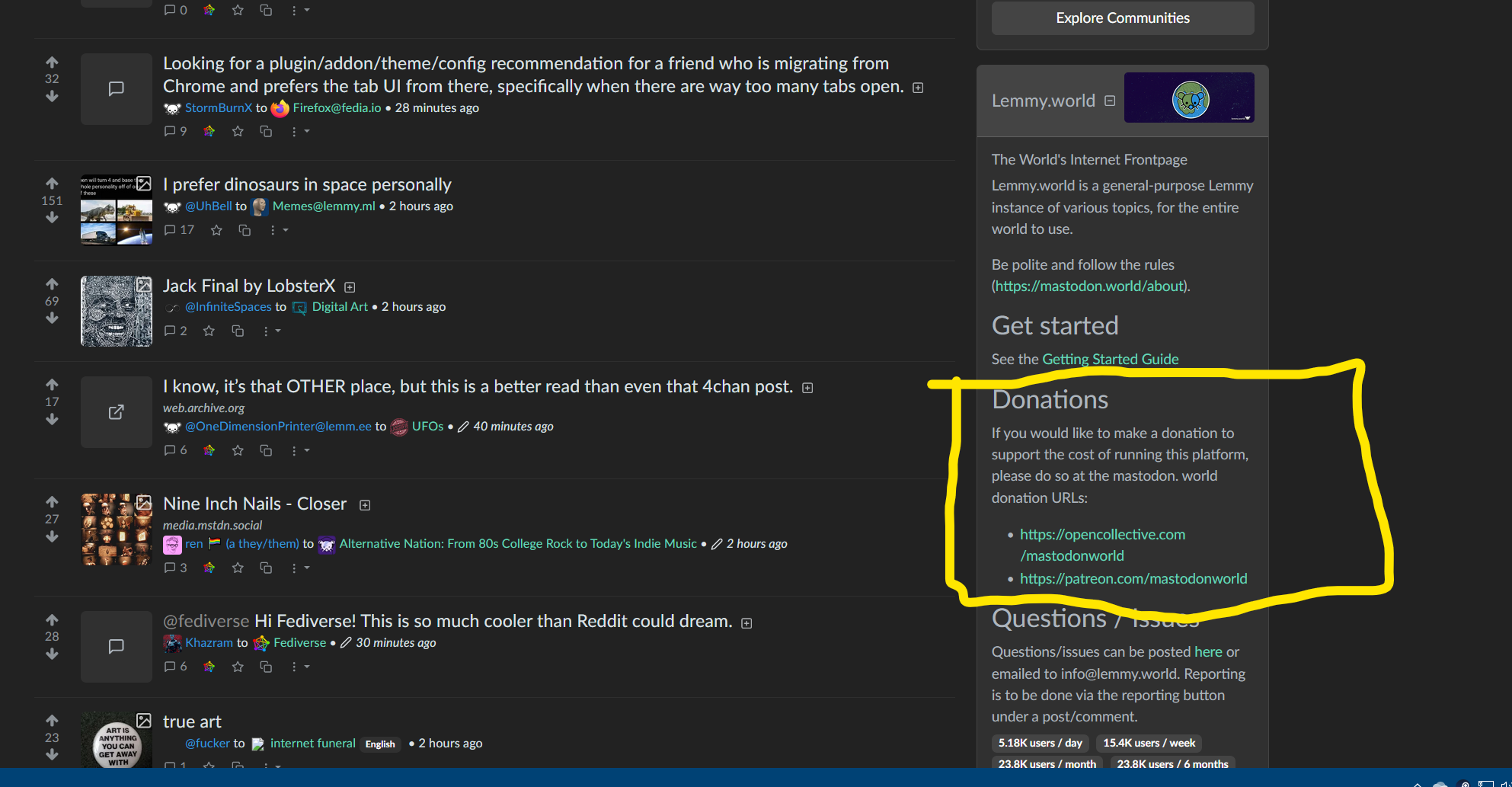
From the lemmy.world front page:
Donations If you would like to make a donation to support the cost of running this platform, please do so at the mastodon.world donation URLs: https://opencollective.com/mastodonworld https://patreon.com/mastodonworldWhere in the frontpage can we see this?
Edit: thank you all!
It’s on the right-hand sidebar of lemmy.world:
Awesome! I’m on mobile, so I cannot see it. Will check it out when I get to my computer.
You can view sidebar on mobile. I think it’s in the three dots, but it’s somewhere!
EDIT: On Jerboa it’s under Community Info, under the three dots. On the mobile web app for L.W. there’s a sidebar button.
Just go to lemmy.world and click sidebar.
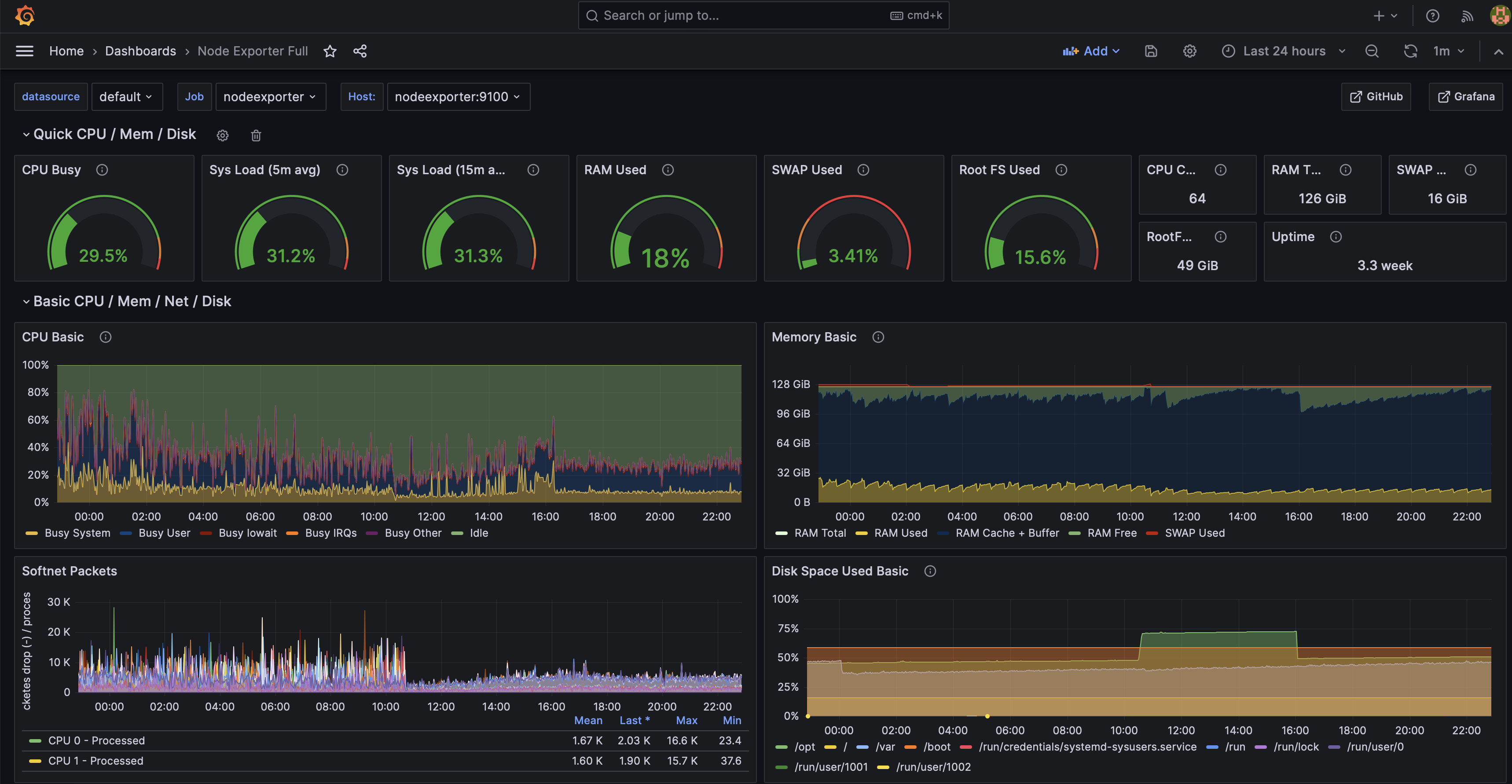
Dang that’s a lot of RAM
mastodon.world has the same server but with twice the RAM :-)
What chassis? I’ve got 256GB in an R720 but only 32 cores here!
It’s a AX161 server at Hetzner
€142 is more reasonable than I expected! I’ll toss some cash to help!
deleted by creator
How much is that in beans?
About tree fiddy
At least 1
Possibly 2
Let’s not go crazy
Is the memory leak still there?
No! Restarts are disabled and it’s OK now!
Great! 😁 I was just wondering because the memory graph showed sharp falls in memory usage every ~30 mins.
That is probably the Garbage Collector running.
Rust has no garbage collector though. Memory is freed up as soon as the variable leaves the current scope.
I’m guessing the server was still set up to restart every 30 mins at the time this pic was taken. Then they tried disabling that and it was fine.
It was mildly educated guess, I know very little about Rust.
Some of my usage is in this data and I like that.
This is awesome! As a systems engineer for my day job, I love seeing stuff like this!
Is there anything Grafana cant do?
I have so many things pumping data “into” Grafana these days I’m surprised they haven’t tried to force me to pay for an enterprise license.
Anyway, thanks for sharing these, @ruud@lemmy.world. As a performance engineer, I love to see this level of detail and commitment on your part to keep the user experience for lemmy.world at acceptable levels.
It can’t make me pancakes.
Wrong tool for the job, but if you want to order pizza, you can use terraform:
https://registry.terraform.io/providers/MNThomson/dominos/latest/docs
I suppose you could then feed your Terraform runs into Grafana and use it to track your pizza consumption.
In the early days of the pandemic…and the early days of my Ansible learning…I set up a playbook to scrape several websites for hand sanitizer and Clorox wipes.
If it found one in stock, it would email my cell phone carriers SMS gateway. Tasker would then make a loud audible alert.
Ran for weeks before it found some in stock. And then it did. At 2am. And again at 2:05, and 2:10, and 2:15…
And it was an error on the shops webpage. It wasn’t actually orderable…once it got in your cart, it wouldn’t let you check out.
Bwahaha:
- Even if you do want a pizza, you should probably be careful with this provider. In testing, I once nearly ordered every item on the Domino’s menu, which would probably have been expensive and embarrassing.
Reminds me of the old adage:
A computer lets you make more mistakes faster than any invention in human history – with the possible exceptions of hand guns and tequila.














{kind=link}